
DataBase Model - Considerations
- Intended audience
- Data modeling as a process
- The data model
- The "Star” schema
- The Audience List schema
- Storing additional data in related lists
- Data locking
- List relations
- Indexes
- Relationship constraints
- Other constraints
- Using option lists
- The snowflake model
Intended audience
This information is intended as guidelines for developers, integration specialists or stakeholders with technical expertise supporting or contributing to the data ecosystem surrounding the Selligent by Zeta toolset.
The content of this article requires a working knowledge of:
- Microsoft .NET (preferably C#)
- SQL / T-SQL
- ETL (Extract, Transform and Load) operations
- Data modeling
- Query performance tuning
The primary purpose here is to gain a deeper insight into the Selligent by Zeta toolset offerings for those preparing data feeds to set up and/or support journeys.
This document contains descriptions about setting up data exchanges with the Selligent by Zeta platform. It will also provide more insights on addressing and translating project requirements, on a campaign level, in order to support the variety of campaigns required. Those reading this manual should then be able to recognize and use the different building blocks Selligent by Zeta provides to set up data feeds – both from a conceptual and technical point of view.
Data modeling as a process
Those that will be designing and implementing a data model for Business units will follow a simple process:
1. Understand Business unit use cases — Understand the business, the vision, desired outcomes, and their perspective upon the role of Selligent by Zeta in delivering business value. Obtaining use cases for all marketing campaigns is essential to gain a deeper insight into how Selligent by Zeta platforms are intended to be used.
2. Understand Business unit data — Each field of each record needs to be clarified for business use in relation to current and future use cases. Data needs to be analyzed and assessed more for what is not needed to be held within Selligent by Zeta: a good rule-of-thumb is quite simply: is this data needed for selection or personalization? If not needed for either, consider it out-of-scope.
3. Design the data model — Begin with an Audience List in the center of a star model then connect related data held in additional lists to this central point.
4. Initial List Population — This should be performed as a one-off import but may require the provided data to be transformed and translated into a format prior to importing.
5. Ongoing Data Exchange — The business may require data from external systems to be kept in synch with Selligent by Zeta, either bringing fresh data into the platform (e.g.: new contacts) or have appraising external systems of campaign outcomes (e.g.: preference changes). Selligent by Zeta provides functionality for Extract, Transform and Load (ETL) operations to maintain data consistency. Only incremental changes (not full loads) are accepted once the initial load has taken place.
The data model
Before designing a data model for the client, a thorough understanding of the way Selligent by Zeta holds data is required. Without this knowledge, the final design may not be compatible with Selligent best practice and therefore runs the risk of introducing issues later in the marketing life cycle, including (but not limited to):
- Data redundancy — Storing unneeded data causes confusion and hinders work
- Data duplication — Having the same data in different places causes either the risk of outdated/inaccurate data being used or additional synchronization issues
- Over-complicated queries — The model should facilitate quick and easy retrieval; poor initial data design makes life difficult for the marketer later
- Complex integration work — The process of connecting Selligent platforms to external systems (Data Warehouses, CRMs, etc) becomes unnecessarily convoluted due to unforeseen issues
- Performance degradation — Not using data retrieval enhancements (e.g.: indexes, option lists, etc) can result in slower queries, prolonging journey execution duration
- Unnecessary costly reworking — Amending and correcting a poorly-designed model that already contains business data can increase the costs of data manipulation work required to preserve this existing data.
Those familiar with databases should understand typical relational database models which store data in a normalized way, eliminating performance issues and storage overhead caused by unnecessary data duplication. Applications typically use relational database models due to efficiency in data storage and information retrieval.
Because of technical and functional reasons, Selligent utilizes a star data model (a de-normalized relational model) which is very easy to understand and query to the end user. This model can be extended to a snowflake for specific purposes.
The "Star” schema
The star data model is the simplest of data schema, consisting of one central table referencing any number of related tables:

For Selligent, at the center lies an Audience List containing contacts as the intended target for campaigns. All records in related lists (sometimes referred to as “child tables”) should have traceability back to a contact in the Audience List; data that cannot be related back has no value in Selligent and should be considered out-of-scope for data exchange processes. Of course, there is the exception of a catalog, which is stored in an unrelated table.
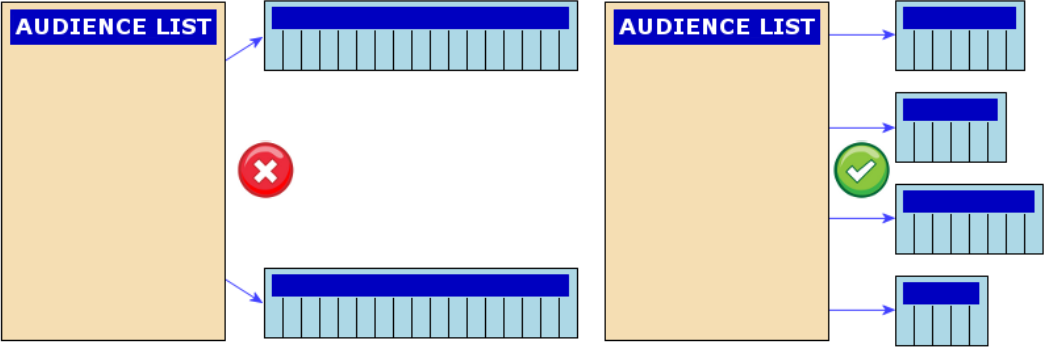
One Audience List: a single source of truth
How many Audience Lists should an Business unit have? There should be the least amount possible – ideally one - providing a single source of truth across all campaigns, but it is perfectly acceptable to use multiple Audience Lists when there is a complete segregation between records in each list (for example: B2B versus B2C).
Multiple Audience Lists containing overlapping contacts give rise to several issues:
- Changes to records in one list must propagate to other lists. Consider a contact amending a mobile phone entry: This change must be synchronized across multiple Audience Lists, so having just the one contact record ensures the change takes place in one location.
- Consolidating duplicate accounts across multiple Audience Lists is near-impossible, as they may not share the same related data structures (different IDs in differing lists)
- Potential legal issues when opting out from one list is not replicated to another list, giving the impression that the opt
- out request has been ignored.
- A single invalid email address in one Audience List is flagged invalid according to predefined bounce rules. The same email address existing across multiple Audience Lists will repeat the same error, lowering sender reputation each time, causing delays in delivery (or no delivery at all).
- A contact existing in multiple Audience Lists may be confused when receiving conflicting messages from different campaigns.
Consequently, a decision about multiple Audience Lists is very difficult to reverse in future:
- Data consolidation of separate Audience Lists (each with their own campaigns) requires a considerable amount of custom work in merging disparate contact lists into one unified Audience List
- Historical data of previous campaigns may be lost or rendered useless
Hence it is strongly recommended to keep to a single Audience List, using segments to divide up records according to business need.
The Audience List schema
An Audience List contains 15 default fields, with the (NUMERIC) ID being the primary key. Information about these fields – their use and data types (standard MS-SQL Server datatypes) - can be found in the online documentation, and it is recommended that those working with Selligent data familiarize themselves thoroughly with these fields, data types and usage.
It is possible to add further fields to the Audience List, but consider:
- If this field is to be used in almost every segment (e.g.: customer account number) for the purpose of selecting or personalizing then consider adding it to the Audience List.
- If not, then this information should be stored in separate lists (profile extensions and/or lookup tables) and related back to this list.
Storing additional data in related lists
As mentioned previously, additional information about contacts should be stored in separate Data Lists then related back to the Audience List (i.e.: the “petals” of the star). Data sharing a common purpose should be grouped together into their own entities (lists) using grouping criteria such as:
- Contextual, e.g.: delivery address, survey results, preferences, subscriptions, etc
- Functional, i.e.: selection or personalization.
For data efficiency and performance reasons, the approach of a larger number of related lists each containing a smaller number of fields (narrower tables) is preferable over a smaller number of related lists with many unrelated fields (wider tables):
However, attempting higher granularity by splitting related data into their own individual lists introduces an unnecessary effort overhead on the part of the marketer when having to seek out related data dissipated across different lists.
Consequently, thought should be given to the level of granularity that provides sufficient data efficiency yet supports the marketer needs – a compromise must be made.
Data locking
Almost every action taken by a contact causes their profile information to be fetched from the Audience List. If the Audience List is unavailable (e.g.: becomes locked for some reason), queries must wait until the list becomes accessible.
Locking occurs during:
- Maintenance actions (index rebuilds),
- Load of new data (Import Tasks)
- A record change (insert/update) against a list.
Consequently, lists (and fields) should be kept as narrow as possible to reduce lock duration.
Note that table locks can also occur if long-running tasks are running concurrently with journey execution, preventing mail delivery. Consideration should be given to how journey windows influence the scheduling of Data Exchange jobs.
How wide are my tables?
A question often asked is: "What is the maximum amount of fields (datatypes + lengths) supported by Selligent before performance is impacted?" It is important to understand that this is not a limitation set by Selligent, but rather a limitation of the underlying database.
Selligent uses Microsoft SQL Server (> 2016 SP1) which recommends a maximum theoretical data size of a single record: 8060 bytes. Records above this size are split with parts stored to a secondary location within the data file (LOB), meaning that multiple fetches are required per record, which tremendously hurts performance – which is why LONG data types - nVarChar(MAX) – are discouraged, and workarounds should be in place to break up large blocks of text for mail body content.
This 8060-byte limit is described in more detail at: https://technet.microsoft.com/en-us/library/ms186981(v=sql.105).aspx
Note that this 8060-byte limit should not be considered an "upper limit” for maximum record size – as mentioned earlier lists should be kept as narrow as possible for performance reasons. Narrower tables also help when applying performance enhancements (like indexes) in future.
List relations
Every action within the Selligent platform retrieves information primarily from the Audience List, using relations when data is stored in additional related lists. There are two types of relationship:
- 1:1 relation — Known as a profile extension: data is accessible for both personalization and selection.
- 1:N relations — Known as lookup tables: data is accessible for both personalization and selection.
To reduce in/out operations when retrieving data from related lists it is recommended to create relationships using fields with the smallest possible datatype, i.e.: NUMERIC fields (4-byte integers).
Note: There may be situations in which a contact in an Audience List can only be identified with a GUID or text string with no options to use alternative keys. For these cases, consider applying recommendations mentioned later.
Indexes
Every list in Selligent by Zeta has an ID field which:
- Is a primary key (unique, not null)
- Uses a clustered index
Additional indexes can be created for lists, but a list may have only one clustered index:
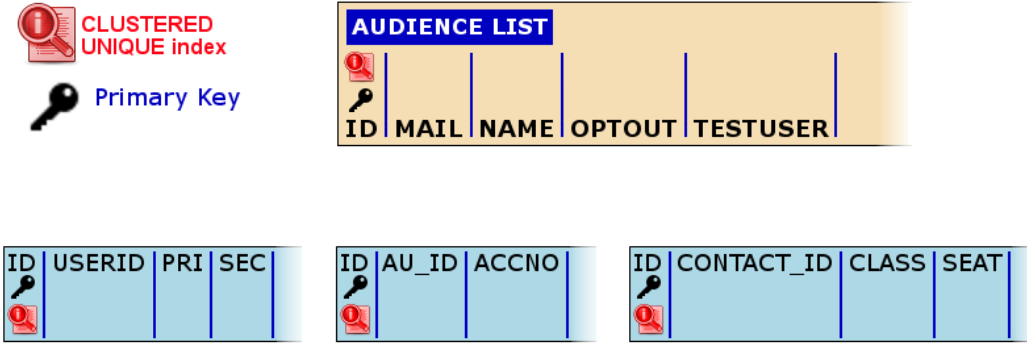
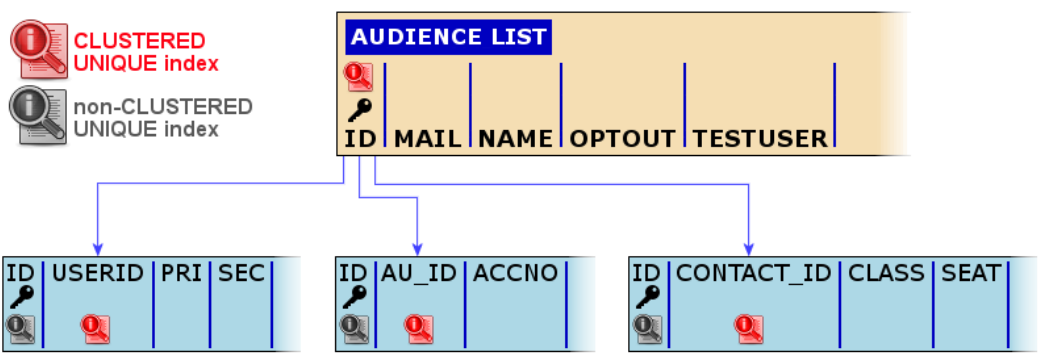
When retrieving contact information, data is always retrieved using the ID field of the Audience List (MASTER.ID), so queries against that field returns results quickly. However, when creating relations, MASTER.ID is usually linked to another field of a related list, e.g.: USERID, AU_ID, CONTACT_ID, etc:

For these profile extensions, it is recommended to:
1. Move the default indexes — Change the unique clustered index of that related list to the foreign key field (which can be performed by the Integration or DBA team).
2. Replace the primary key constraint on that list's ID field, which places a unique non-clustered index against this field. Some platform actions still retrieve list data using the ID field, so the ‘unique’ definition of this constraint ensures that queries are still supported and properly indexed.
If the above is not an option, it is recommended to force uniqueness of the 1:1 profile extension by placing (non-clustered) unique indexes on fields used for relationships the extended profile and the
Audience List on the field that holds the key value:
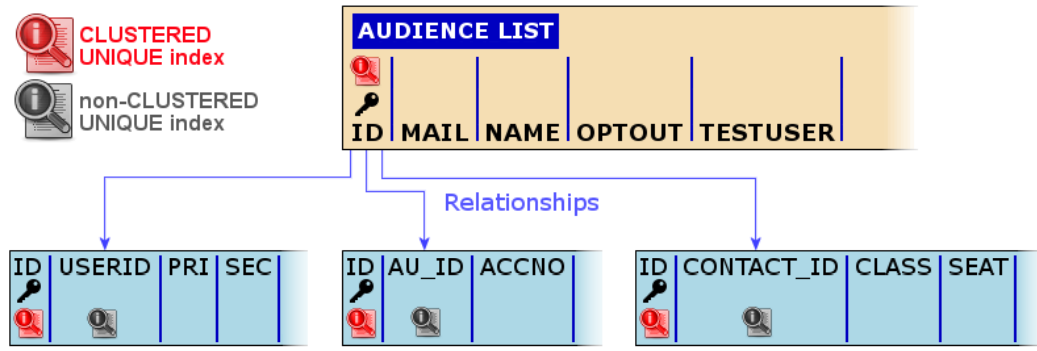
This setup cannot be used for 1:N relationships (lookups) as the foreign key may be repeated, so only non-unique indexes can be used. In this situation, the recommendation is:
1. Leave the primary key and clustered index on the ID field of that lookup list but place a non-clustered (non-unique) index that includes (but is not limited to) the foreign key field.
2. Alternatively, create a clustered non-unique index on the foreign key field (but leave the primary key constraint on the ID field).
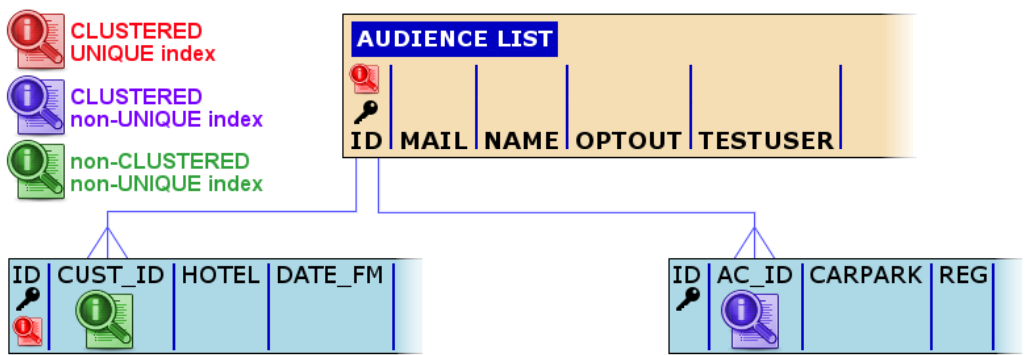
The exact definition of this non-clustered index will depend on the (variety of) selections intended to query this list.
To index or not to index?
Indexes dramatically speed up searches so are of paramount importance when creating segments or filters. However, given they create a performance overhead when data changes (inserts and updates) their use should be carefully considered – over-indexing can easily generate more problems. If possible, check execution plans and performance of queries before finalizing indexes.
Some candidates for indexing are:
- JOIN fields — Columns used to create relationships between lists (discussed earlier)
- Selective fields — Columns used during selections, either for filters or segments
- Sort fields — Used in data selectors to order content presented in the message.
Note that indexes are only used if less than 15% of the data in that list is queried – above that there will be a full table scan anyway. Consequently, adding an index to the related column for lookups is beneficial for about 90% of situations; again, it helps to understand the use cases for which related data will be utilized.
Uniqueness: Yes or no?
Depending upon business policy, there can be significant benefits to keeping the email address unique in the Audience List, preventing duplications and therefore avoiding the need to perform deduplication actions during a journey. This can be achieved by placing a Unique Index (non-clustered) against the MAIL field:

Other fields could be considered candidates for uniqueness: MOBILE, etc. However, the additional overhead this may place on data writes must be taken into consideration with regards to data volatility, especially if unique constraints are placed on fields that are part of a regular import job.
Relationship constraints
- Add an entry to a child for a contact that does not exist in the parent (Audience List)
- Remove contacts from the parent and leave orphaned records in child lists.
Referential integrity can be enforced by specifying constraints as part of the model design and implementing such constraints as part of the initial build (it is much more difficult to add them to retrospectively). However, the benefits of adding such constraints introduces complications during constraint violations, e.g.:
- Adding a preference to a profile extension for an ID that doesn’t exist in the Audience List
- Attempting to remove a contact for which supplementary business data still exists
- Duplicating the contact ID in a profile extension
The platform’s reporting of constraint violations is not considered informative; error messages may confuse a marketer who is prevented from performing an operation but not told why.
Other constraints
Other than the PRIMARY KEY constraint against a list’s ID column (and content validation against a column’s data type), no other constraints exist by default. Further constraints may be considered:
- CHECK constraints to ensure only specific values are accepted (e.g.: BOOKING_DT must be after today)
- NOT NULL to prevent a column from being left blank (e.g.: BIRTHDATE column)
- UNIQUE to prevent duplication (e.g.: two employees sharing the same payroll number)
However, documentation should reflect these constraints (even just the description field) to avoid confuse and frustration when a data operation fails with a cryptic message.
Using option lists
Option Lists should be used when normalizing enumerated field values, almost providing a PK/FK relationship between that column and the defined permitted values. For example, consider a scenario in which a contact fits one of three categories ("new", "engaged", "lapsed"):
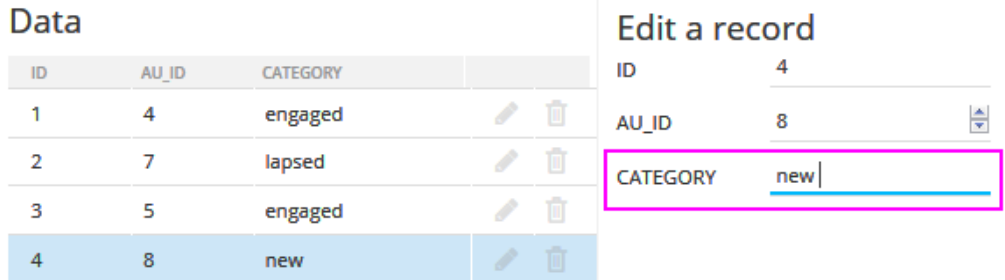
Storing this category as a text field means repeating the same content for the entire set of records, making it costly in terms of:
- data storage — Each character takes 2 bytes of storage (plus an overhead of 2 bytes), so "engaged" requires 16 bytes per record when storing/retrieving those records
- selection criteria — Searches must perform text comparisons with the amount of I/O operations increasing per character. Even for only three values, there needs to be 7 comparisons to exactly match "engaged".
An Option List works like a lookup table using a CODE (integer field) that references the unique (translated) values the field can hold:

Once a field uses this option list, the translated values are presented (rather than CODE):
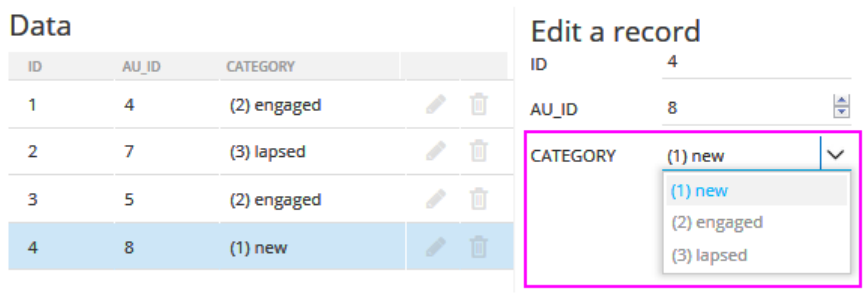
The list does not need to store the full range of text values but rather store just the CODE, a 4-byte integer value. Advantages to this approach are:
- Sanity — An enumerated set of values prevent mistyping and data variations
- Storage efficiency — Rather than the full text string, the data/Audience List stores only the foreign key (a numeric)
- Selection performance — The lookup compares an integer value, not the full text string.
Indexing this field yields even greater performance gains.
Option lists will provide the ability to use data for both selection and personalization.
Multiple fields or records?
When storing preference data, a tendency is to create a profile extension containing several fields, one for each preference for that record, for example:

This design may incur drawbacks:
- selections that look for several preferences need to query several fields using OR logic
- newer preferences require structural changes to the list (additional fields manually added)
- space is wasted in storing fields with no content when no preference is given
Redesigning this structure to a 1:N relationship in which each record (row) depicts a preference:
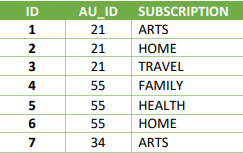
This redesign brings significant advantages:
- selections that look for several preferences can query one field using an “IS ONE OF” clause
- newer preferences are treated as just another record being added
- no space is wasted as no preferences given means no record is needed to be stored
Further optimizations are possible by using an Option List for the SUBSCRIPTION column:
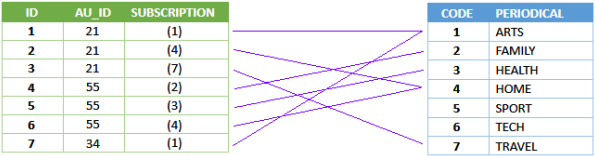
The snowflake model
As previously mentioned, the standard data model for Selligent by Zeta is a star model.
However, it is possible to extend existing relationships, resulting in a snowflake model:
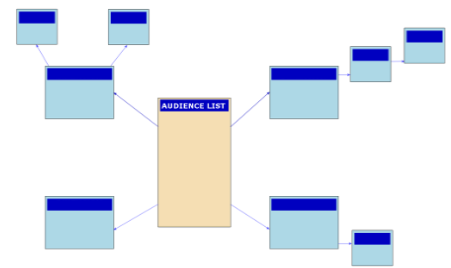
The maximum amount of nested tables linked in a 1:N relationship is limited to SEVEN, but in practise performance issues have arisen when more than FOUR are used. It is recommended to keep this number low.
