The Datasets shared with me provide access to the standard Marigold Engage data. These include datasets owned by anyone (including me) and datasets not owned by me. Currently following datasets are available (for a detailed overview of the shared datasets, check out this topic):
- Communication stats : This dataset contains all the communications per contact and all the interactions on it. Typically fields available in this dataset are emails sent, delivered, viewed, clicked.
- Communications Overview : This dataset contains all the communications and all the interactions on it. Typically fields available in this dataset are emails sent, delivered, viewed, clicked. This data set is different from the Communication stats dataset in a way that it does not contain data on contact level but only aggregated data. This has a positive impact on performance.
Note: The Communication Stats and Communication Overview datasets take into account historical data of the last 14 months for the initial load. However, for all new interactions, these are only taken into account if they are related to communications done this month or the previous month. New interactions on older communications are not included in the aggregates.
- Consumer engagement stats: View on all consumers and their engagement. This dataset currently supports the standard fields in an Audience List or 1:1 linked list such as email, language, optout, maildomain, subscribe source, etc- as well as the most common custom fields (such as Subscribe- source, Bounce count, Gender, Birthday, Age, country,...).
Note: The Consumer datasets are built on a single Audience List. The default Audience List is based on the list with the smallest ID. If you want the stats to be based on a different Audience List a filter on the ListID must be added to the dashboard and the right list needs to be selected from the drop-down.
Note that it is also possible to configure the database and define the default Audience List to be used. Please contact Marigold to set this up for you.
Datasets owned by me — Datasets uploaded by the user (e.g. a CSV file, or connection to a database such as Google Big Query). These datasets are managed by the user only. Calculated fields can be added. The owner of the dataset can share it with other users.
Public datasets — Datasets available to everyone. For example a world map with demographic information. These datasets are not linked to Marigold Engage.
Data types
The data in the datasets can be of 4 different types. Each type has a dedicated icon:
![]() Hierarchy - Describes mutual exclusive things such as gender, channel type, journey type etc. These can be strings and numerics and can be used as categories and to group data.
Hierarchy - Describes mutual exclusive things such as gender, channel type, journey type etc. These can be strings and numerics and can be used as categories and to group data.
![]() Date time - Such as year, month, week, day, hour, minute, second. These show an evolution over time and can also be used in filters.
Date time - Such as year, month, week, day, hour, minute, second. These show an evolution over time and can also be used in filters.
![]() Measures - Numerical values used within calculations (e.g. emails sent, delivered, opened, ..) Aggregates can be created on these measures.
Measures - Numerical values used within calculations (e.g. emails sent, delivered, opened, ..) Aggregates can be created on these measures.
Note: Measures cannot be used as category in a graph.
Topography - Defines a location (e.g. longtitude, latitude). This is used to represent data on maps
Viewing a dataset
To view the details of a dataset, click on it in the overview of datasets:
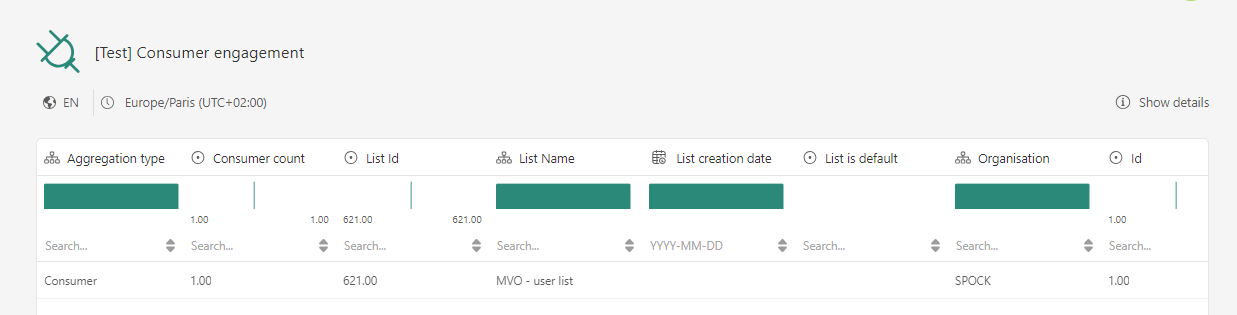
The structure and data of the selected dataset is displayed:
Creating a calculated field (Only in Data Studio Pro)
You can create your own calculated fields on your own dataset and datasets that are shared with you.
To create a calculated field, open the dataset of your choice
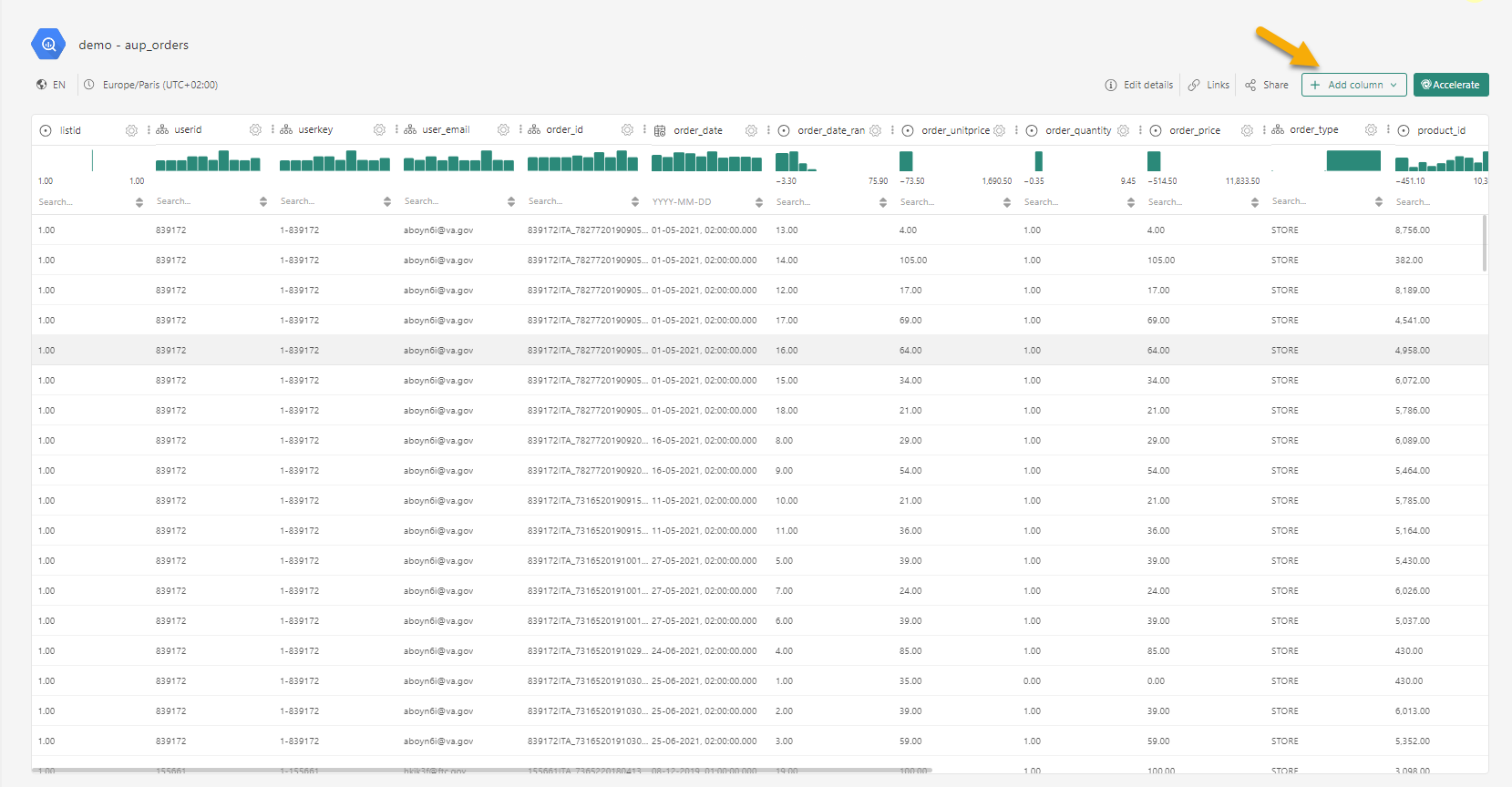
Click Add column and configure the calculated field:
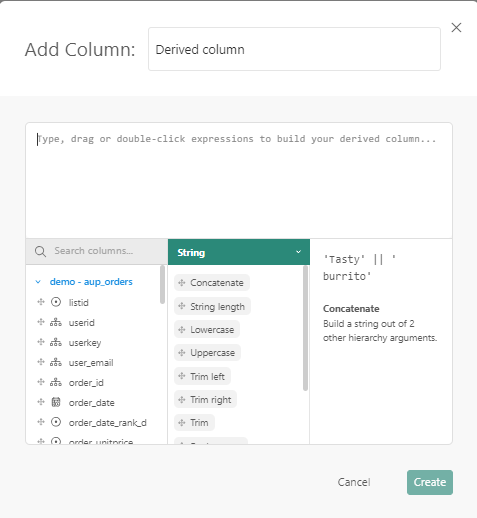
On the left, you can use the columns in the dataset and drag them to the white canvas above.
The middle section allows to select the function to apply. The drop-down field at the top allows to select first the type of function (string, mathematical, conversion, etc) and then the function. An explanation of what the function does and the parameters is available from the right. Drag and drop the selected function onto the white canvas above.
Example:
Use the column Journey_Type and apply a conditional function 'IsEmpty' where empty values are replaced with 'Unknown' value. When selecting the function and dropping it onto the canvas, placeholders are available where the columns can be dropped upon.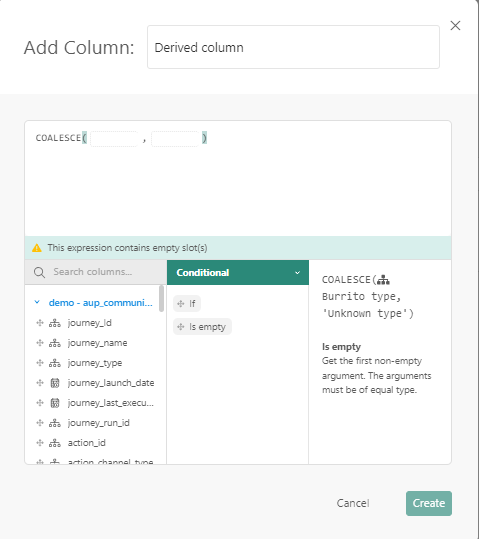
Drag the column Journey_type onto the first placeholder and enter a value for the second placeholder.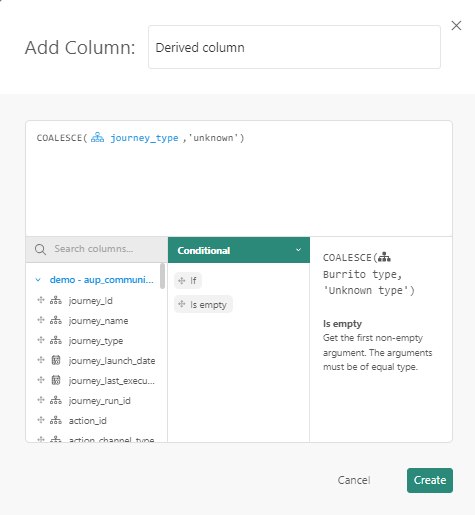
Creating your own datasets (Only in Data StudioPro)
Data Studio Pro users have the possibility to create their own datasets using multiple different sources. To do this, go to the Datasets tab in Data Studio.
Multiple options are available:
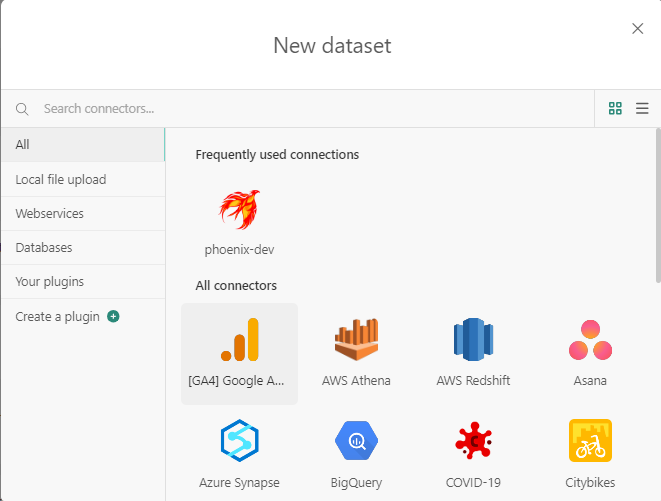
- Local file upload such as a CSV file.
- Webservices such as Google Analytics and Google Drive.
- Databases such as SQLServer, MySQL,Oracle, etc.
- Plugins such as BigQuery.
Depending on the selected connection type, different connection parameters need to be filled out.
Note: When loading data from a CSV file into the dataset, this operation will need to be re-executed regularly to keep the data up to date. However, when connecting to a cloud data storage location, data will always be up to date.
Google Analytics

You'll be asked by Google to sign in and grant access to access your Analytics data. If you’re not the owner of the site ("web property") Google Analytics account, make sure the e-mail address you're signing in to with Google has at least Read permissions.
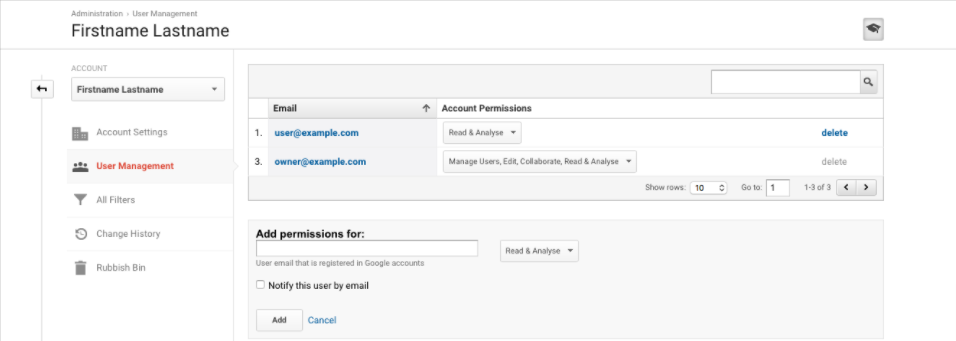
After accepting, you should be able to import data directly from Google Analytics!

BigQuery
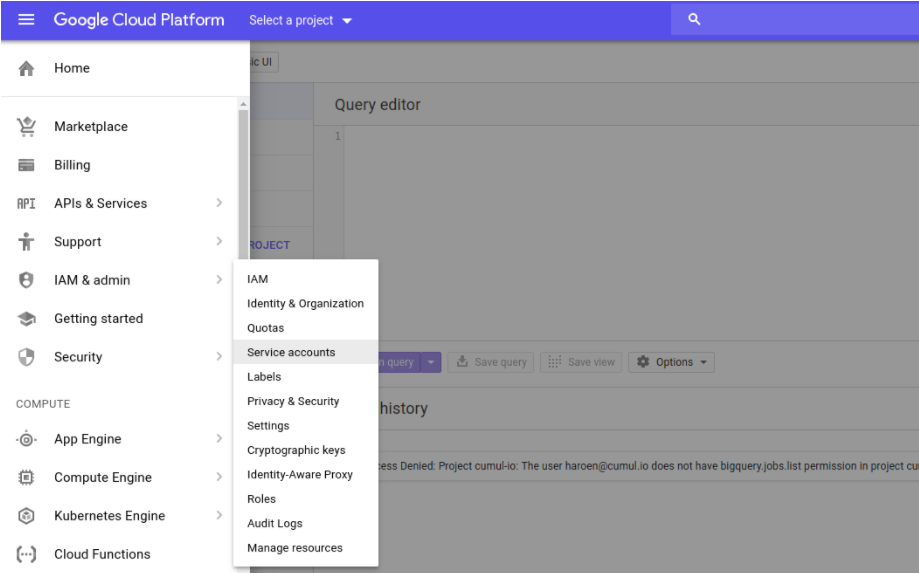
First setup a service account to access BigQuery :
Go to Google Cloud Console and select IAM & admin tab from the left menu. Click on Service accounts from the list.
Click Create new service account and give it a name of your choice . Select BigQuery Admin from the role drop down and check Furnish a new private key.
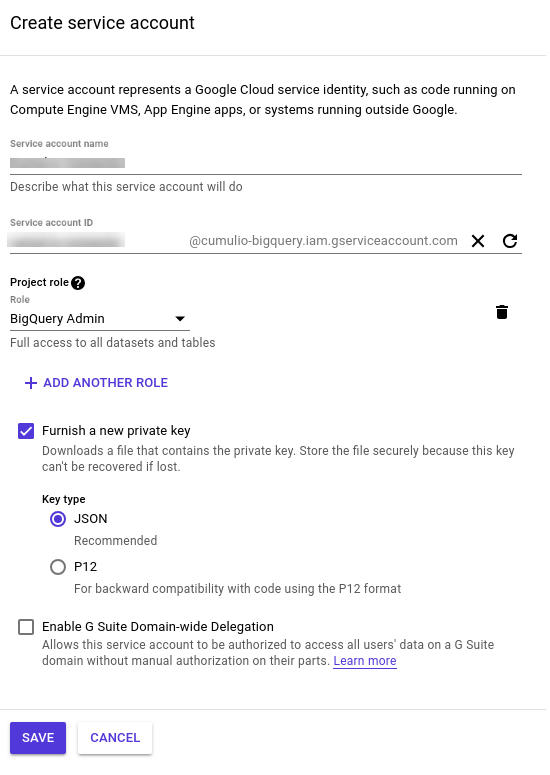
Once created, a JSON with the credentials will be downloaded automatically.
Navigate to the Datasets tab and click 'New dataset'. Select the 'BigQuery' connector. You'll be asked to provide a key and token. Copy these verbatim from the JSON file:
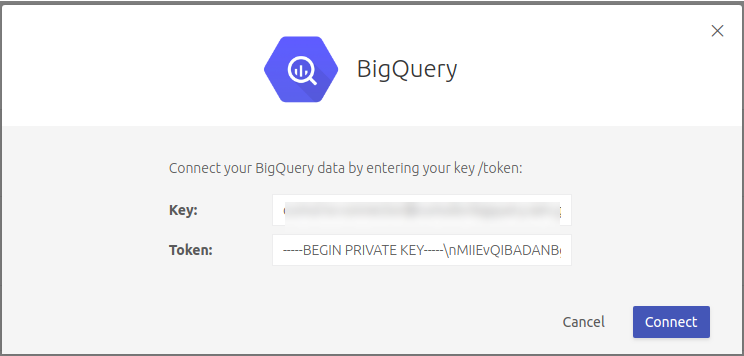
Copy the value of JSON field client-email as key.
Copy the value of JSON field private-key as token.
Oracle client
Navigate to the Datasets tab and click 'New dataset'. Select the 'Oracle' connector. You'll be asked to provide a host, key and token:
- Host: This is the query string to connect your Oracle database, eg. my-oracle-host.com:1521/database-sid
- Key: The username of the Oracle user. We advise to create a separate read-only technical user for connecting Cumul.io to your Oracle databases.
- Token: The password of the Oracle user
After connecting, you can now select, connect and visualize your Oracle data.
Note: Make sure to whitelist following range of IP addresses in your Oracle server if external connections are blocked:
88.99.71.232 ( proxy-a.cumul.io)
52.213.28.47 ( proxy-b.cumul.io)
